【PostgreSQL】レンジパーティションによる検索処理の実行速度への影響を検証する
検証目的
PostgreSQLにおいてレンジパーティションを作成することで検索処理の実行時間を向上させることができるか検証します。今回検証する処理は以下の2つです。
- 単一テーブルに対する検索処理
- 親子関係のテーブルを結合しての検索処理
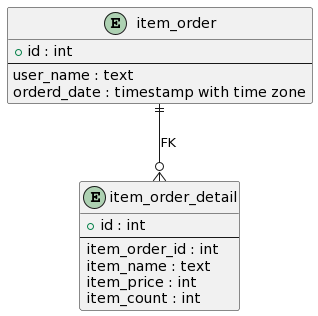
親子関係のテーブルでパフォーマンス検証するため、以下のような注文データと注文明細データを格納するテーブルを作成します。検証用テーブルなのでカラムは適当です。
レンジパーティションはorder_dateに対して作成します。日々蓄積されていく注文データに対して注文日によるパーティションを作成することでパフォーマンスが向上するか検証します。
検証環境
本記事の検証は以下の環境で行なっています。
- MacBook Pro 2023 M2Max
- PostgreSQL 15.4
テーブル作成
上記のER図のテーブルを作成します。item_orderテーブルは注文日であるorder_dateによるレンジパーティションあり・なしのテーブルを作成します。
レンジパーティションなしテーブル
以下のDDLを使用しテーブルを作成しました。
create table item_order (
id int,
user_name text,
orderd_date timestamp with time zone,
primary key (id)
);
create table item_order_detail (
id int primary key,
item_order_id int,
item_name text,
item_price int,
item_count int,
foreign key(item_order_id) references item_order(id)
);テーブル定義を確認します。
test_db2=# \d+ item_order
Table "public.item_order"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
-------------+--------------------------+-----------+----------+---------+----------+-------------+--------------+-------------
id | integer | | not null | | plain | | |
user_name | text | | | | extended | | |
orderd_date | timestamp with time zone | | | | plain | | |
Indexes:
"item_order_pkey" PRIMARY KEY, btree (id)
Referenced by:
TABLE "item_order_detail" CONSTRAINT "item_order_detail_item_order_id_fkey" FOREIGN KEY (item_order_id) REFERENCES item_order(id)
Access method: heapレンジパーティションありテーブル
item_orderに対してレンジパーティションを作成します。検証用として2020年の1~12月の注文データを格納するパーティションを作成します。
create table item_order (
id int,
user_name text,
orderd_date timestamp with time zone,
PRIMARY KEY (id, orderd_date)
) PARTITION BY RANGE (orderd_date);
create table item_order_detail (
id int primary key,
item_order_id int,
item_name text,
item_price int,
item_count int,
foreign key(item_order_id) references item_order(id)
);
-- 2020年の各月ごとにレンジパーティションを作成
create table item_order_2020_1 partition of item_order for values from ('2020-01-01 00:00:00') to ('2020-02-01 00:00:00');
create table item_order_2020_2 partition of item_order for values from ('2020-02-01 00:00:00') to ('2020-03-01 00:00:00');
create table item_order_2020_3 partition of item_order for values from ('2020-03-01 00:00:00') to ('2020-04-01 00:00:00');
create table item_order_2020_4 partition of item_order for values from ('2020-04-01 00:00:00') to ('2020-05-01 00:00:00');
create table item_order_2020_5 partition of item_order for values from ('2020-05-01 00:00:00') to ('2020-06-01 00:00:00');
create table item_order_2020_6 partition of item_order for values from ('2020-06-01 00:00:00') to ('2020-07-01 00:00:00');
create table item_order_2020_7 partition of item_order for values from ('2020-07-01 00:00:00') to ('2020-08-01 00:00:00');
create table item_order_2020_8 partition of item_order for values from ('2020-08-01 00:00:00') to ('2020-09-01 00:00:00');
create table item_order_2020_9 partition of item_order for values from ('2020-09-01 00:00:00') to ('2020-10-01 00:00:00');
create table item_order_2020_10 partition of item_order for values from ('2020-10-01 00:00:00') to ('2020-11-01 00:00:00');
create table item_order_2020_11 partition of item_order for values from ('2020-11-01 00:00:00') to ('2020-12-01 00:00:00');
create table item_order_2020_12 partition of item_order for values from ('2020-12-01 00:00:00') to ('2021-01-01 00:00:00');テーブル定義を確認します。月毎のデータを格納するパーティションが作成されていることを確認します。
test_db1=# \d+ item_order
Partitioned table "public.item_order"
Column | Type | Collation | Nullable | Default | Storage | Compression | Stats target | Description
-------------+--------------------------+-----------+----------+---------+----------+-------------+--------------+-------------
id | integer | | not null | | plain | | |
user_name | text | | | | extended | | |
orderd_date | timestamp with time zone | | not null | | plain | | |
Partition key: RANGE (orderd_date)
Indexes:
"item_order_pkey" PRIMARY KEY, btree (id, orderd_date)
Partitions: item_order_2020_1 FOR VALUES FROM ('2020-01-01 00:00:00+00') TO ('2020-02-01 00:00:00+00'),
item_order_2020_10 FOR VALUES FROM ('2020-10-01 00:00:00+00') TO ('2020-11-01 00:00:00+00'),
item_order_2020_11 FOR VALUES FROM ('2020-11-01 00:00:00+00') TO ('2020-12-01 00:00:00+00'),
item_order_2020_12 FOR VALUES FROM ('2020-12-01 00:00:00+00') TO ('2021-01-01 00:00:00+00'),
item_order_2020_2 FOR VALUES FROM ('2020-02-01 00:00:00+00') TO ('2020-03-01 00:00:00+00'),
item_order_2020_3 FOR VALUES FROM ('2020-03-01 00:00:00+00') TO ('2020-04-01 00:00:00+00'),
item_order_2020_4 FOR VALUES FROM ('2020-04-01 00:00:00+00') TO ('2020-05-01 00:00:00+00'),
item_order_2020_5 FOR VALUES FROM ('2020-05-01 00:00:00+00') TO ('2020-06-01 00:00:00+00'),
item_order_2020_6 FOR VALUES FROM ('2020-06-01 00:00:00+00') TO ('2020-07-01 00:00:00+00'),
item_order_2020_7 FOR VALUES FROM ('2020-07-01 00:00:00+00') TO ('2020-08-01 00:00:00+00'),
item_order_2020_8 FOR VALUES FROM ('2020-08-01 00:00:00+00') TO ('2020-09-01 00:00:00+00'),
item_order_2020_9 FOR VALUES FROM ('2020-09-01 00:00:00+00') TO ('2020-10-01 00:00:00+00')テストデータ投入
以下のSQLを使用しテーブルにテスト用データを投入します。2020年1月1日〜2020年12月31日までの注文データのイメージです。
insert into item_order (id, user_name, orderd_date)
select
i,
'user' || i,
timestamp '2020-01-01 00:00:00' + random() * (timestamp '2020-12-31 23:59:59' - timestamp '2020-01-01 00:00:00')
from
generate_series(1, 1000000) AS i;
insert into item_order_detail (id, item_order_id, item_name, item_price, item_count)
SELECT
(o.id - 1) * 10 + d,
o.id,
'item' || d,
(d * 100),
d
FROM
item_order o,
generate_series(1, 10) AS d; パフォーマンス検証
以下のSQLを実行し、2,3月の注文データを検索した場合の実行計画と実行時間を確認します。
テーブル結合なし
explain analyze select * from item_order o1 where o1.orderd_date between '2020-02-01 00:00:00' and '2020-03-31 00:00:00';レンジパーティションなし
test_db2=# explain analyze select * from item_order o1 where o1.orderd_date between '2020-02-01 00:00:00' and '2020-03-31 00:00:00';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------
Seq Scan on item_order o1 (cost=0.00..21370.00 rows=162524 width=22) (actual time=0.121..87.688 rows=160970 loops=1)
Filter: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-03-31 00:00:00+00'::timestamp with time zone))
Rows Removed by Filter: 839030
Planning Time: 0.193 ms
Execution Time: 92.933 msレンジパーティションあり
2, 3月データが格納されているパーティションから検索されていることがわかります。検索範囲が限定される分実行速度が向上しています。
test_db1=# explain analyze select * from item_order o1 where o1.orderd_date between '2020-02-01 00:00:00' and '2020-03-31 00:00:00';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------
Append (cost=0.00..4298.02 rows=160778 width=22) (actual time=0.029..38.609 rows=160807 loops=1)
-> Seq Scan on item_order_2020_2 o1_1 (cost=0.00..1690.11 rows=79058 width=22) (actual time=0.027..11.461 rows=79074 loops=1)
Filter: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-03-31 00:00:00+00'::timestamp with time zone))
-> Seq Scan on item_order_2020_3 o1_2 (cost=0.00..1804.01 rows=81720 width=22) (actual time=0.027..12.652 rows=81733 loops=1)
Filter: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-03-31 00:00:00+00'::timestamp with time zone))
Rows Removed by Filter: 2668
Planning Time: 0.425 ms
Execution Time: 45.629 msテーブル結合あり
以下のSQLを実行し、2月の注文データと注文明細データを結合し検索した場合の実行計画と実行時間を確認します。
explain analyze select * from item_order o1 inner join item_order_detail o2 on o1.id = o2.item_order_id where o1.orderd_date between '2020-02-01 00:00:00' and '2020-02-28 00:00:00';レンジパーティションなし
test_db2=# explain analyze select * from item_order o1 inner join item_order_detail o2 on o1.id = o2.item_order_id where o1.orderd_date between '2020-02-01 00:00:00' and '2020-02-28 00:00:00';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Gather (cost=13998.71..203009.35 rows=727121 width=44) (actual time=74.198..489.797 rows=735890 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Hash Join (cost=12998.71..129297.25 rows=302967 width=44) (actual time=38.799..432.908 rows=245297 loops=3)
Hash Cond: (o2.item_order_id = o1.id)
-> Parallel Seq Scan on item_order_detail o2 (cost=0.00..105361.13 rows=4166613 width=22) (actual time=0.504..166.519 rows=3333333 loops=3)
-> Parallel Hash (cost=12620.00..12620.00 rows=30297 width=22) (actual time=37.235..37.235 rows=24530 loops=3)
Buckets: 131072 Batches: 1 Memory Usage: 5088kB
-> Parallel Seq Scan on item_order o1 (cost=0.00..12620.00 rows=30297 width=22) (actual time=9.562..32.252 rows=24530 loops=3)
Filter: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-02-28 00:00:00+00'::timestamp with time zone))
Rows Removed by Filter: 308804
Planning Time: 0.617 ms
JIT:
Functions: 36
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 2.454 ms, Inlining 0.000 ms, Optimization 1.650 ms, Emission 24.342 ms, Total 28.446 ms
Execution Time: 507.368 ms
(17 rows)レンジパーティションあり
テーブル結合のためのParallel Hashに時間がかかり、レンジパーティションなしに比べて大幅に実行速度が遅くなっています。
test_db1=# explain analyze select * from item_order o1 inner join item_order_detail o2 on o1.id = o2.item_order_id where o1.orderd_date between '2020-02-01 00:00:00' and '2020-02-28 00:00:00';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
Gather (cost=182857.79..288019.52 rows=768299 width=44) (actual time=8844.287..12049.474 rows=736180 loops=1)
Workers Planned: 1
Workers Launched: 1
-> Parallel Hash Join (cost=181857.79..210189.62 rows=451941 width=44) (actual time=8804.174..11450.044 rows=368090 loops=2)
Hash Cond: (o1.id = o2.item_order_id)
-> Parallel Seq Scan on item_order_2020_2 o1 (cost=0.00..1201.71 rows=43335 width=22) (actual time=0.039..2.538 rows=36809 loops=2)
Filter: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-02-28 00:00:00+00'::timestamp with time zone))
Rows Removed by Filter: 2728
-> Parallel Hash (cost=105361.13..105361.13 rows=4166613 width=22) (actual time=8391.308..8391.308 rows=5000000 loops=2)
Buckets: 131072 Batches: 128 Memory Usage: 5440kB
-> Parallel Seq Scan on item_order_detail o2 (cost=0.00..105361.13 rows=4166613 width=22) (actual time=0.418..299.100 rows=5000000 loops=2)
Planning Time: 6.197 ms
JIT:
Functions: 24
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 1.694 ms, Inlining 0.000 ms, Optimization 1.306 ms, Emission 20.366 ms, Total 23.366 ms
Execution Time: 12067.083 ms
(17 rows)インデックス追加
検索条件に使用しているordered_dateと結合キーであるitem_order_idに対してインデックスを作成しパフォーマンスがどのように変わるか確認します。
create index idx_order_date ON item_order(orderd_date);
create index idx_item_order_id ON item_order_detail(item_order_id);インデックス追加後のパフォーマンス検証
テーブルのデータ数と実行したSQLはインデックス追加前と同じです。
テーブル結合なし
以下のSQLを実行し、2,3月の注文データを検索した場合の実行計画と実行時間を確認します。
explain analyze select * from item_order o1 where o1.orderd_date between '2020-02-01 00:00:00' and '2020-03-31 00:00:00';パーティションなし
検索にインデックスが使用されており、インデックス追加前より実行速度が向上しています。
test_db2=# explain analyze select * from item_order where orderd_date between '2020-02-01 00:00:00' and '2020-03-31 00:00:00';
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on item_order (cost=3454.30..12262.16 rows=162524 width=22) (actual time=15.553..49.462 rows=160970 loops=1)
Recheck Cond: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-03-31 00:00:00+00'::timestamp with time zone))
Heap Blocks: exact=6370
-> Bitmap Index Scan on idx_order_date (cost=0.00..3413.67 rows=162524 width=0) (actual time=14.226..14.226 rows=160970 loops=1)
Index Cond: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-03-31 00:00:00+00'::timestamp with time zone))
Planning Time: 0.190 ms
Execution Time: 55.372 ms
(7 rows)パーティションあり
2, 3月のデータが格納されたレンジパーティション内のデータを全件検索するSQLのためパーティション内でインデックスは使われず、実行計画に変化はありません。
test_db1=# explain analyze select * from item_order where orderd_date between '2020-02-01 00:00:00' and '2020-03-31 00:00:00';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------
Append (cost=0.00..4298.14 rows=160803 width=22) (actual time=0.017..41.493 rows=160807 loops=1)
-> Seq Scan on item_order_2020_2 item_order_1 (cost=0.00..1690.11 rows=79074 width=22) (actual time=0.015..13.996 rows=79074 loops=1)
Filter: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-03-31 00:00:00+00'::timestamp with time zone))
-> Seq Scan on item_order_2020_3 item_order_2 (cost=0.00..1804.01 rows=81729 width=22) (actual time=0.015..11.905 rows=81733 loops=1)
Filter: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-03-31 00:00:00+00'::timestamp with time zone))
Rows Removed by Filter: 2668
Planning Time: 0.438 ms
Execution Time: 49.055 ms
(8 rows)テーブル結合あり
こちらもインデックス追加前と同じ以下のSQLを実行し、2月の注文データと注文明細データを結合し検索した場合の実行計画と実行時間を確認します。
explain analyze select * from item_order o1 inner join item_order_detail o2 on o1.id = o2.item_order_id where o1.orderd_date between '2020-02-01 00:00:00' and '2020-02-28 00:00:00';パーティションなし
test_db2=# explain analyze select * from item_order o1 inner join item_order_detail o2 on o1.id = o2.item_order_id where o1.orderd_date between '2020-02-01 00:00:00' and '2020-02-28 00:00:00';
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Gather (cost=9748.90..198761.11 rows=727130 width=44) (actual time=73.307..493.736 rows=735890 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Hash Join (cost=8748.90..125048.11 rows=302971 width=44) (actual time=30.984..429.303 rows=245297 loops=3)
Hash Cond: (o2.item_order_id = o1.id)
-> Parallel Seq Scan on item_order_detail o2 (cost=0.00..105361.67 rows=4166667 width=22) (actual time=0.321..169.462 rows=3333333 loops=3)
-> Parallel Hash (cost=8370.19..8370.19 rows=30297 width=22) (actual time=29.450..29.451 rows=24530 loops=3)
Buckets: 131072 Batches: 1 Memory Usage: 5120kB
-> Parallel Bitmap Heap Scan on item_order o1 (cost=1545.73..8370.19 rows=30297 width=22) (actual time=4.121..18.208 rows=24530 loops=3)
Recheck Cond: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-02-28 00:00:00+00'::timestamp with time zone))
Heap Blocks: exact=5834
-> Bitmap Index Scan on idx_order_date (cost=0.00..1527.56 rows=72713 width=0) (actual time=11.044..11.044 rows=73589 loops=1)
Index Cond: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-02-28 00:00:00+00'::timestamp with time zone))
Planning Time: 2.892 ms
JIT:
Functions: 36
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 3.718 ms, Inlining 0.000 ms, Optimization 1.537 ms, Emission 18.410 ms, Total 23.665 ms
Execution Time: 511.026 ms
(19 rows)パーティションあり
結合キーであるitem_order_idにインデックスを作成したことでテーブルの結合がNest Loopとなりました。インデックスを使用することで結合処理が高速になり、全体の実行時間も大きく向上しています。
test_db1=# explain analyze select * from item_order o1 inner join item_order_detail o2 on o1.id = o2.item_order_id where o1.orderd_date between '2020-02-01 00:00:00' and '2020-02-28 00:00:00';
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.43..286818.71 rows=768392 width=44) (actual time=9.664..229.776 rows=736180 loops=1)
Workers Planned: 1
Workers Launched: 1
-> Nested Loop (cost=0.43..208979.51 rows=451995 width=44) (actual time=7.277..165.479 rows=368090 loops=2)
-> Parallel Seq Scan on item_order_2020_2 o1 (cost=0.00..1201.71 rows=43339 width=22) (actual time=6.983..10.949 rows=36809 loops=2)
Filter: ((orderd_date >= '2020-02-01 00:00:00+00'::timestamp with time zone) AND (orderd_date <= '2020-02-28 00:00:00+00'::timestamp with time zone))
Rows Removed by Filter: 2728
-> Index Scan using idx_item_order_id on item_order_detail o2 (cost=0.43..4.69 rows=10 width=22) (actual time=0.001..0.003 rows=10 loops=73618)
Index Cond: (item_order_id = o1.id)
Planning Time: 0.598 ms
JIT:
Functions: 16
Options: Inlining false, Optimization false, Expressions true, Deforming true
Timing: Generation 2.230 ms, Inlining 0.000 ms, Optimization 0.669 ms, Emission 12.964 ms, Total 15.863 ms
Execution Time: 247.747 ms
(15 rows)まとめ
レンジパーティションを作成することで、単一テーブルに対する検索処理ではインデックス作成前でも期待通り実行速度の向上が確認できました。
インデックス作成前では親子関係をのテーブルを結合しての検索処理ではレンジパーティションを作成した場合、テーブル結合に時間がかかりレンジパーティションなしより実行速度が遅いという予想外の結果となりました。データ数や実行したSQLにも影響を受けると思うので、今回の結果のみではレンジパーティションを作成すると遅くなるとは言えません。
インデックスを作成した場合、結合処理が高速化されレンジパーティションありの方が実行速度が早くなりました。インデックス設計と検証が重要だと改めて実感しました。
当然ですが、レンジパーティションを作成したら必ず速くなる or 遅くなるというわけではないので、データ数やデータの分布、実行したい処理を考慮したテーブル・インデックス設計、きちんとした動作検が必要ですね。